
Python challenge 3 - How fast can a computer read all of Wikipedia?
The website Wikipedia is consistently ranked amongst the most-visited websites in the world, and contains a huge amount of content. If a website contains a large database with information available to all internet users, then it helps to be able to automate the accessing of that information for further analysis.
How fast can a computer read all of Wikipedia?
Automating accessing of database information can be done through an Application Programming Interface, or API.
In the case of Wikipedia, this information is in the form of text strings. The systematic analysis of strings to study their properties is sometimes called text analytics. It can be used in a range of settings and used for studying large volumes of text far greater than a human could ever read in a lifetime.
This challenge looks at using a simple API for accessing Wikipedia content, and then running some simple text analytics functions on the resulting data.
Target:
Write one page of Python that will:
- Search and select the ‘Hello World’ page, then print the ‘Summary’ to the terminal.
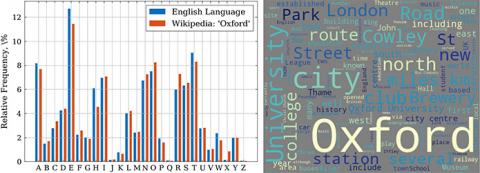
- Run frequency analysis (i.e. count the occurrences of each letter) on the content of the ‘Oxford’ page.
- Create a Wordcloud for the ‘Content’ data from a page of your choice.
Extensions:
- Starting at a page of your choice, choose a random link on the page, and print the title of the page selected.
- Repeat the above random link selection 20 times, printing the title of each site you visit.
- Estimate how long it would take to read all of Wikipedia by calling pages from this API.
Try to get as far as you can on your own before viewing the hints or the solution
-
Hints for Python Challenge 3
Packages
- In this challenge we use Wikipedia as a wrapper to call the Wikipedia API. As this is a Python wrapper, it is relatively straightforward to access documentation using the help() command within Python.
- To create the Wordcloud, we used the wordcloud package, although it would be possible to create your own Wordcloud using a powerful technique called regular expressions. However, we do not explicitly use these in this challenge.
Hints
- Python has a wide range of built-in commands for analysing string data. Try and use this functionality without writing your own code, where possible.
- The API requires quite specific page names to withdraw the information. Using the results of the wikipedia.search might help find the specific page name you are looking for.
Notes
- The relative frequency of characters is probably the simplest analysis that can be done from text data - search for the Text Mining page to find out more on this topic.
- You are likely to find that it would take a very long time for a computer to ‘read’ all of Wikipedia using the API. What is the bottleneck?
-
Solution for Python Challenge 3
# ===== Challenge 3: How fast can a computer read all of Wikipedia? import numpy as np import matplotlib.pyplot as plt import wikipedia, random, time, string # 1. Load the content of the 'hello world' page and print. hello_search = wikipedia.search('Hello world') page = wikipedia.WikipediaPage(hello_search[0]) print(page.summary) # 2. Run frequency analysis on the Oxford page string. oxford_search = wikipedia.search('Oxford') page = wikipedia.WikipediaPage(oxford_search[0]) oxford_text = page.content # Set known frequencies of letters in the English alphabet letter_freqs = [8.16, 1.49, 2.78, 4.25, # A, B, C, D 12.70, 2.23, 2.02, 6.09, # E, F, G, H 6.97, 0.15, 0.77, 4.02, # I, J, K, L 2.40, 6.74, 7.50, 1.92, # M, N, O, P 0.09, 5.98, 6.32, 9.05, # Q, R, S, T 2.75, 0.97, 2.36, 0.15, # U, V, W, X 1.97, 0.07] # Y, Z # Create dictionary to record frequency of letters # The initial frequency is set as zero, i.e. {A:0, B:0, ... Z:0} rel_freqs = dict.fromkeys(string.ascii_uppercase, 0) n_letters = 0 for letter in rel_freqs.keys(): # Get the letter frequency from the Oxford page letter_count = oxford_text.upper().count(letter) # Set the frequncy of the letter in the dictionary rel_freqs[letter] = letter_count # Record total number of letters, ignoring spaces, punctuation etc. n_letters = n_letters + letter_count # Calculate the relative frequencies of each letter for the Oxford page rel_freq_oxf = 100 * np.array(list(rel_freqs.values()))/n_letters # Plot frequencies as a bar chart plt.bar(np.arange(26)-0.25, letter_freqs, width=0.3, label='E.L. Freq.') plt.bar(np.arange(26)+0.25, rel_freq_oxf, width=0.3, label='\'Oxford\'') plt.xticks(np.arange(26), labels=rel_freqs.keys()) plt.ylabel('Relative Frequency, \%') plt.legend() plt.show() # 3. Make a wordcloud of the page of text for Oxford. from wordcloud import WordCloud from random import random wordcloud = WordCloud().generate(oxford_text) plt.imshow(wordcloud, interpolation='bilinear') plt.show() # Extension 1 & 2: Cycle through random pages starting at a page. sandwich_search = wikipedia.search('Ham and Cheese Sandwich') page = wikipedia.WikipediaPage(sandwich_search[0]) for i in range(10): try: random_page = page.links[int(random() * len(page.links))] page = wikipedia.WikipediaPage(random_page) print(random_page) except: print('Page Error! try a different link.') pass # Extension 3: How long would it take to read wikipedia using this API? t = time.time() for i in range(10): random_page = wikipedia.WikipediaPage(wikipedia.random()) # Calculate time in hours. time_to_read = (time.time() - t) * (48174651/10)/3600 # in hours. print(str(time_to_read) + " hours")
Ready for the next challenge?
Click here to explore 'How long it would take to walk every street in Oxford'